
이전 포스트에서 2개의 클래스를 분류하는 모델을 만들어보고 예측까지 해보았습니다.
이번 포스트에서는 2개 이상의 클래스를 분류하는 다중 분류 모델을 만들어보겠습니다.
이전 포스트와 거의 유사하니 이전 포스트를 참고해주세요!
https://sanmldl.tistory.com/15
신경망을 이용한 이진 분류: 영화 리뷰 분류
지금까지 다룬 내용을 바탕으로 신경망에서 가장 많이 다루는 이진 분류, 다중 분류, 회귀의 실제 문제를 풀어볼 예정입니다. 이번 포스트에서는 그 중에서 이진 분류의 문제를 다뤄보도록 하겠
sanmldl.tistory.com
뉴스 기사 분류: 다중 분류
-로이터(Reuter) 데이터셋
로이터 데이터셋은 짧은 뉴스기사와 토픽을 매칭한 데이터 셋입니다.
46개의 토픽이 있으며 각 토픽은 최소한 10개의 샘플을 가지고 있습니다.
해당 데이터셋은 케라스에 포함되어 있어 임포트하기 쉽습니다.
코드는 다음과 같습니다.
from tensorflow.keras.datasets import reuters
(train_data, train_label),(test_data, test_label) = reuters.load_data(num_words = 10000)해당 데이터 셋에는 8,982개의 훈련 샘플과 2,246의 테스트 샘플이 있습니다.
또한 각 샘플은 정수 리스트입니다.(단어 인덱스)
IMDB 리뷰데이터와 비슷합니다.
여기서도 num_words 매개변수를 통해 가장 자주 사용된 단어 10000개에 대해 데이터를 가져옵니다.
label은 46의 토픽을 표현해야 하므로 0~45사이의 정수가 될 것입니다.
로이터 기사 데이터도 인코딩의 과정이 필요합니다.
영어 단어를 어떤 특정한 숫자로 표현하는 것이죠.
그렇다면 반대로 인코딩된 숫자 리스트를 디코딩하면 뉴스 기사가 되겠네요!
디코딩에 대한 코드는 다음과 같습니다.
#decoding
word_index = reuters.get_word_index()
reverse_word_index = dict([(value,key) for (key,value) in word_index.items()])
decoded_newswire = " ".join([reverse_word_index.get(i-3, "?")for i in train_data[0]])train_data의 첫 번째 인덱스에 있는 뉴스기사에 대한 내용이 디코딩될 것입니다.
사용할 데이터를 벡터화시켜야 합니다.
이전 포스트에서 설명한 것과 같은 원리입니다.
코드는 다음과 같습니다.
import numpy as np
def vectorize_sequences(sequences, dimension = 10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
for j in sequence:
results[i, j] = 1
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
입력 데이터뿐만 아니라 label에 대해서도 벡터화시켜줘야 합니다. 그 이유는 이진분류와 달리 다중 분류에 대해
모델이 예측을 할 수 있어야 하기 때문입니다. 이때 쓰이는 것이 원-핫 인코딩 방식입니다.
범주형 데이터에 널리 사용됩니다.
각 레이블의 인덱스자리가 1이고 나머지가 0인 벡터입니다.
이를 코드로 구현하면 다음과 같습니다.
#원-핫 인코딩
def one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
이처럼 직접 함수로 구현하여 사용해도 되지만 케라스는 이와 같은 내장 함수가 따로 있습니다.
코드는 다음과 같습니다.
from tensorflow import keras
from keras.utils.np_utils import to_categorical
y_train = to_categorical(train_label)
y_test = to_categorical(test_label)
-모델 구성
다중 분류를 위한 신경망 모델을 먼저 구성해야 합니다.
코드는 다음과 같습니다.
from keras import layers
model = keras.Sequential([
layers.Dense(64, activation = 'relu'),
layers.Dense(64, activation = 'relu'),
layers.Dense(46, activation = 'softmax')
])여기서 주목할 것은 출력 노드 개수, 즉 각 층의 크기가 64, 64, 46이며 마지막 층의 활성화함수가 softmax라는 것입니다.
46개의 토픽을 분류해야 하므로 마지막 층의 크기는 46이며, 다중 분류에서는 마지막 활성화 함수로 softmax를 사용하곤 합니다.
N개의 클래스의 대한 확률 분포를 출력하기 위함입니다.
또한 다중 분류에서 사용하는 최적의 손실함수는 categorical_crossentropy입니다.
이 함수는 두 확률 분포 사이의 거리를 측정합니다.
모델이 출력한 확률 분포와 실제 값의 확률 분포사이의 거리를 구해 최적의 파라미터를 찾는 것입니다.
두 확률 분포사이의 거리가 최소가 될 때 최적의 파라미터가 될 것입니다.
모델 컴파일을 위한 코드는 다음과 같습니다.
model.compile(
optimizer = 'rmsprop',
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
-훈련 검증
검증을 위한 검증데이터를 따로 만들겠습니다.
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = y_train[:1000]
partial_y_train = y_train[1000:]
검증 데이터가 준비가 됐으면 이제 훈련을 시킬 차례입니다!
에포크를 20으로 두고 훈련을 진행해 보겠습니다.
history = model.fit(partial_x_train, partial_y_train, epochs = 20, batch_size = 512, validation_data = (x_val, y_val))
이진 분류때와 마찬가지로 손실과 정확도에 대한 곡선을 시각화해 보겠습니다.
import matplotlib.pyplot as plt
history_dict = history.history
loss_value = history_dict['loss']
val_loss_value = history_dict['val_loss']
plt.plot(loss_value, 'bo', label = 'training loss')
plt.plot(val_loss_value, 'b', label = 'validation loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend()
plt.show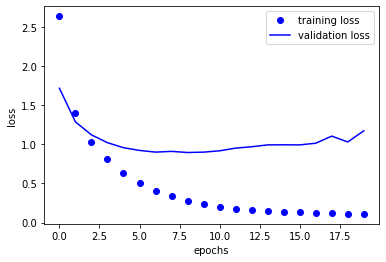
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
plt.clf()
plt.plot(acc, 'bo', label = 'training accuracy')
plt.plot(val_acc, 'b', label = 'validation accuracy')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.legend()
plt.show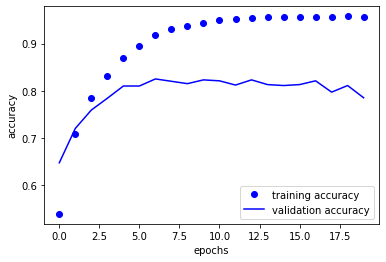
이 모델은 직관적으로 9번째 에포크 이후에서 과대적합이 이뤄지는 것을 알 수 있습니다.
따라서 에포크를 9로 하여 새로운 학습을 진행시켜 보겠습니다.
model2 = keras.Sequential([
layers.Dense(64, activation = 'relu'),
layers.Dense(64, activation = 'relu'),
layers.Dense(46, activation = 'softmax')
])
model2.compile(
optimizer = 'rmsprop',
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
model2.fit(partial_x_train, partial_y_train, epochs = 9, batch_size = 512, validation_data = (x_val, y_val))
results = model2.evaluate(x_test, y_test)결과를 확인하면 거의 80%에 가까운 정확도를 보여줍니다.
새로운 샘플에 대한 모델의 예측을 하려면 각 샘플에 대해 46개의 클래스 확률 분포를 반환시켜
가장 큰 확률을 보이는 인덱스가 모델이 예측하는 토픽이 됩니다.
10개의 테스트 데이터에 대한 예측 토픽을 예측해보겠습니다.
코드는 다음과 같습니다.
predictions = model.predict(x_test)
for i in range(10):
result = np.argmax(predictions[i])
print(result)
10개의 테스트 데이터에 대한 토픽들을 예측하는 것을 확인할 수 있습니다!
이번 포스트에서는 다중 분류를 위한 마지막 출력층의 활성화함수를 softmax를 사용했습니다.
또한 범주혀 크로스엔트로피를 사용하여 확률 분포와 타깃 분포의 거리를 최소화 했으며
이 때 사용된 손실함수가 categorical_crossentropy입니다.
'Book Review > [케라스 창시자에게 배우는 딥러닝] 리뷰' 카테고리의 다른 글
| 머신러닝의 목표: 일반화 (2) | 2023.01.11 |
|---|---|
| 신경망을 이용한 회귀: 주택 가격 예측 (1) | 2022.12.29 |
| 신경망을 이용한 이진 분류: 영화 리뷰 분류 (2) | 2022.12.28 |
| 텐서플로우를 통한 딥러닝 모델 직접 구현 (0) | 2022.12.07 |
| keras API를 통한 간단한 딥러닝 모델 만들기 (0) | 2022.12.05 |



