
이전의 포스팅에서 Convnet을 통해 이미지 분류 모델을 살펴보고 잘 분류되는 것을 확인할 수 있었습니다.
computer vision분야에서 합성곱 신경망은 주로 다음과 같은 분야에서 활용됩니다.
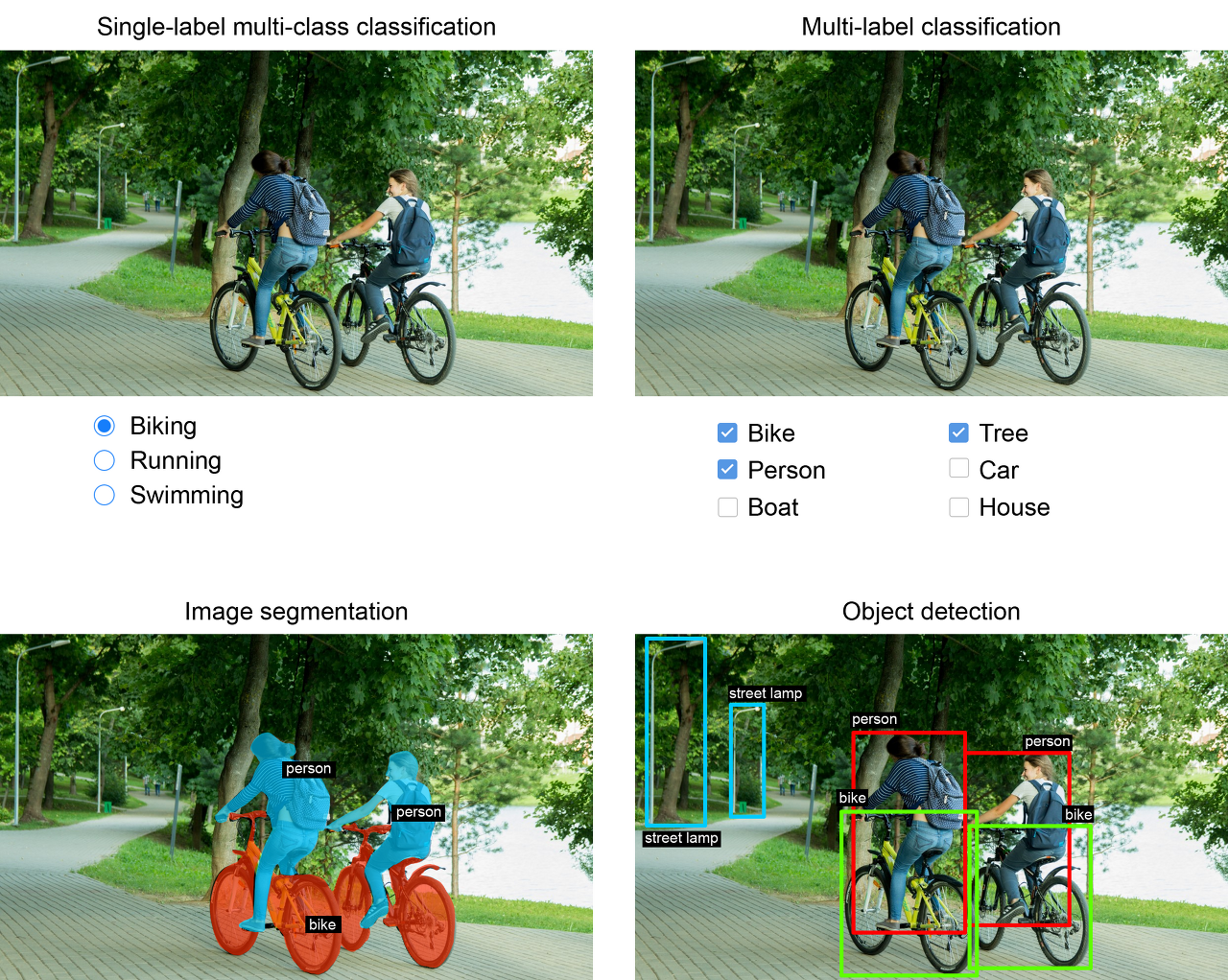
1. 이미지 분류
: 이미지에 포함된 사물의 클래스를 분류하는 것입니다. 이미지 분류에는 크게 두 가지가 있습니다.
- 단일 레이블 분류(single-label classification)
- 예제: 한 장의 사진에서 고양이, 강아지, 사람, 자전거, 자동차 등 중에하 하나의 클래스 선택
- 다중 레이블 분류(multi-label classification)
- 예제: 한 장의 사진에 포함된 여러 종류의 객체를 모두 분류. 예를 들어 두 사람이 자전거를 타는 사진에서 두 사람과 자전거 등 사진에 포함된 모든 객체의 클래서 확인.
2. 이미지 분할
: 이미지를 특정 클래스를 포함하는 영역으로 나눠 분할시키는 것입니다.
- 예제: 줌(Zoom), 구글 미트(Google Meet) 등에서 사용되는 배경 블러처리 기능
3. 객체 탐지
: 이미지에 포함된 객체나 객체 주위에 경계상자 그리는 작업을 의미합니다.
- 예제: 자율주행 자동차의 주변에 위치한 다른 자동차, 행인, 신호등 등 탐지 기능
이 세가지 이외에도 최근에는 더욱 다양한 컴퓨터 비전 분야로의 응용이 활성화되고 있습니다.
- 이미지 유사도 측정(image similarity scoring): 두 이미지가 시각적으로 얼마나 비슷할까?
- 키포인트 탐지(keypoint detection): 얼굴 특징과 같이 이미지에서 관심 속성을 어떻게 탐지할까?
- 자세 추정(pose estimation), 3D 메쉬 추정(3D mesh estimation) 등 이 있습니다.
객체 탐지와 최근의 컴퓨터 비전 응용은 기초 수준을 넘어서기 때문에 다른 포스팅에서 직접 하나씩 다뤄보도록 하겠습니다.
이번 포스팅에서는 이미지 분할에 대해 알아보도록 하겠습니다.
-이미지 분할 (image segmentation)
이미지 분할은 여러 가지 다른 영역으로 분류해서 분할하는 작업을 의미합니다.
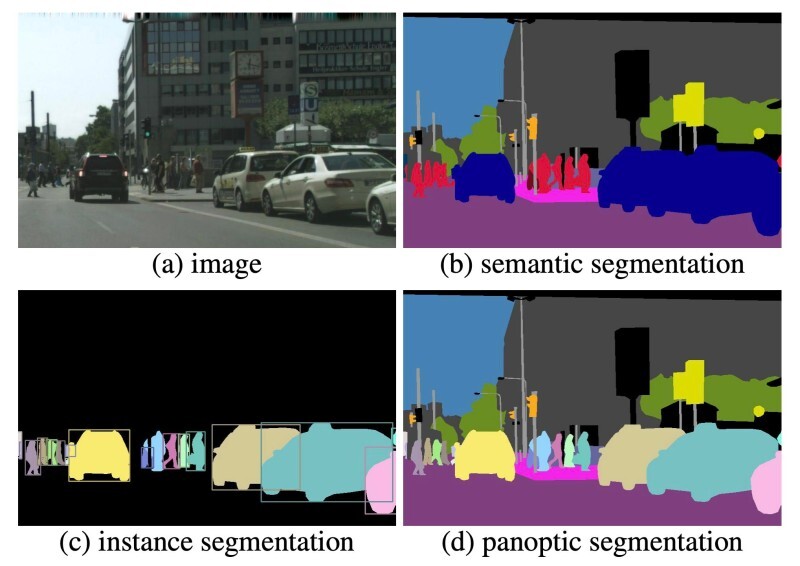
두 가지 종류의 이미지 분할이 있습니다.
1. semantic segmentation
2. instance segmentation
semantic segmentation은 하나의 같은 범주로 분할하는 것이고
instance segmentation은 같은 범주뿐만 아니라 각 객체 인스턴스도 분할하는 것을 의미합니다.
-이미지 분할 적용해보기
그렇다면 이번 예제에서는 이미지 분할 중 시맨틱 분할에 초점을 맞춰 실습을 해보겠습니다.
데이터셋은 강아지와 고양이를 비롯해서 37종의 애완동물의 다양한 크기와 다양한 자세를 담은 7,390장의 사진으로 구성됩니다.
클래스 별 사진수는 200개이며, 사진 별 레이블은 종과 품종, 머리 표시 경계상자,
트라이맵 분할(trimap segmentation) 마스크로 구성되어 있습니다.
트라이맵 분할 마스크는 원본 사진과 동일한 크기의 흑백 사진이며 각각의 픽셀이 1,2,3 중에 하나의 값을 가지고 있습니다.
1은 사물 2는 배경 3은 윤곽입니다.
먼저 터미널에서 wget과 tar 셀 명령어로 데이터를 내려받고 압축을 풀어보겠습니다.
!wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
!wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
!tar -xf images.tar.gz
!tar -xf annotations.tar.gz
이후에 데이터를 불러오기 위해서 압축을 푼 파일에서 입력 파일 경로와 분할 마스크 파일 경로를 각각 리스트로 구성해 보겠습니다.
#입력 파일 경로와 분할 마스크(정답 레이블) 파일 경로를 리스트로 구성
import os
input_dir = 'images/'
target_dir = 'annotations/trimaps/'
input_img_paths = sorted(
[os.path.join(input_dir, fname)
for fname in os.listdir(input_dir)
if fname.endswith('.jpg')]
)
target_paths = sorted(
[os.path.join(target_dir, fname)
for fname in os.listdir(target_dir)
if fname.endswith('.png') and not fname.startswith('.')]
)
확인을 위해 특정 이미지와 분할 마스크를 불러와볼까요?
어떻게 생겼는지 확인이 필요해 보입니다.
#입력과 분할 마스크 샘플 이미지 뽑아보기
import matplotlib.pyplot as plt
from tensorflow.keras.utils import load_img, img_to_array
plt.axis('off')
plt.imshow(load_img(input_img_paths[100]))
#위 이미지에 해당하는 분할 마스크
def display_target(target_array):
normalized_array = (target_array.astype('uint8') - 1 * 127)
plt.axis('off')
plt.imshow(normalized_array[:,:,1])
img = img_to_array(load_img(target_paths[100]))
display_target(img)

데이터가 어떻게 생겼는지 확인했으니 이제 입력과 타깃을 넘파이 배열로 만들어 훈련과 검증 세트로 나눠보겠습니다.
import numpy as np
import random
import matplotlib.pyplot as plt
from tensorflow.keras.utils import load_img, img_to_array
img_size = (200,200)
num_img = len(input_img_paths)
#품종별로 정렬되어 있으므로 파일 경로를 뒤섞는다. 동일한 순서를 유지하도록 시드를 1337로 유지
random.Random(1337).shuffle(input_img_paths)
random.Random(1337).shuffle(target_paths)
def path_to_input(path):
return img_to_array(load_img(path, target_size = img_size))
def path_to_target(path):
img = img_to_array(
load_img(path, target_size = img_size, color_mode = 'grayscale')
)
# 레이블 1,2,3 에서 0,1,2로
img = img.astype('uint8') - 1
return img
#전체 이미지를 float32로 로드하고 타깃 마스크는 uint8로 로드 + 이미지는 3채널 rgb / 타깃은 정수레이블만 담은 하나의 채널
input_imgs = np.zeros((num_img,) + img_size + (3,), dtype = 'float32')
targets = np.zeros((num_img, ) + img_size + (1,), dtype = 'uint8')
for i in range(num_img):
input_imgs[i] = path_to_input(input_img_paths[i])
targets[i] = path_to_target(target_paths[i])
num_val = 1000
train_input_imgs = input_imgs[ :-num_val]
train_tareget = targets[:-num_val]
val_input_imgs = input_imgs[-num_val :]
val_target = targets[-num_val :]
데이터가 준비되었으니 모델을 정의할 차례입니다.
이미지 분할 모델의 구성은 기본적으로 Conv2D 층으로 구성된 다운샘플링 블록(downsampling block)과 Conv2DTranspose 층으로 구성된 업샘플링 블록(upsampling block)으로 이루어집니다.
마찬가지로 모델의 반을 다운샘플링하고 반은 업샘플링하여 모델을 구성해 보겠습니다.
from tensorflow import keras
from tensorflow.keras import layers
def get_model(img_size, num_classes):
inputs = keras.Input(shape = img_size + (3,))
x = layers.Rescaling(1. / 255)(inputs)
#다운샘플링
x = layers.Conv2D(64, 3, strides = 2, activation = 'relu', padding = 'same')(x)
x = layers.Conv2D(64, 3, activation = 'relu', padding = 'same')(x)
x = layers.Conv2D(128, 3, strides = 2, activation = 'relu', padding = 'same')(x)
x = layers.Conv2D(128, 3, activation = 'relu', padding = 'same')(x)
x = layers.Conv2D(256, 3, strides = 2, activation = 'relu', padding = 'same')(x)
x = layers.Conv2D(256, 3, activation = 'relu', padding = 'same')(x)
#업샘플링
x = layers.Conv2DTranspose(256,3, activation = 'relu', padding = 'same')(x)
x = layers.Conv2DTranspose(256,3, strides = 2, activation = 'relu', padding = 'same')(x)
x = layers.Conv2DTranspose(128,3, activation = 'relu', padding = 'same')(x)
x = layers.Conv2DTranspose(128,3, strides = 2, activation = 'relu', padding = 'same')(x)
x = layers.Conv2DTranspose(64,3, activation = 'relu', padding = 'same')(x)
x = layers.Conv2DTranspose(64,3, strides = 2, activation = 'relu', padding = 'same')(x)
outputs = layers.Conv2D(num_classes, 3, activation = 'softmax', padding = 'same')(x)
model = keras.Model(inputs, outputs)
return model처음 절반은 이미지 분류에서 사용한 convnet과 비슷합니다. conv2d층을 쌓고 점진적으로 필터 개수를 늘리는 것입니다.
다운샘플링을 일종의 압축으로 이해하듯이 이 과정에서도 공간상의 각 위치가 원본 이미지에 있는 더 큰 영역에 대한 정보를 담고 있는 것으로 인코딩 된 것입니다.
나머지 절반은 conv2Dtranspose층을 쌓았습니다. 최종 출력은 타깃 마스크의 크기와 동일해야 하므로
지금까지 적용한 변환을 거꾸로 적용할 필요가 있는 것입니다. 이를 나머지 절반에서 수행한 것입니다.
특성 맵을 업샘플링하여 같은 크기의 이미지를 얻을 수 있게 되는 것입니다.
-> 두 과정에서 중요한 것은 stride를 통해 다운, 업샘플링 했다는 것과 최대 풀링을 사용하지 않는다는 점입니다.
우리가 기대하기로 모델의 출력은 픽셀별 타깃 마스크입니다. 정보의 공간상 위치에 많은 관심을 두기 때문에
maxpooling을 사용하지 않습니다. 최대 풀링을 하면 풀링 윈도우 안의 위치 정보가 사라지기 때문입니다.
결국 maxpooling을 통한 다운샘플링은 이미지 분할에서 잘 작동하는 것을 의미합니다.
모델을 정의했으니 이제 컴파일하고 훈련해 보겠습니다.
model.compile(
optimizer = 'adam',
metrics = ['accuracy'],
loss = 'sparse_categorical_crossentropy'
)
callback = keras.callbacks.ModelCheckpoint('oxford.keras', save_best_only = True)
history = model.fit(train_input_imgs, train_tareget, epochs= 50, callbacks = callback, batch_size = 64, validation_data = (val_input_imgs, val_target))
훈련과 검증에 대한 손실을 모니터링해보겠습니다.
#손실 모니터링
epochs = range(1, len(history.history['loss']) + 1)
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure()
plt.plot(epochs, loss, 'bo', labels='training loss')
plt.plot(epochs, val_loss, 'b-', labels='validation loss')
plt.legend()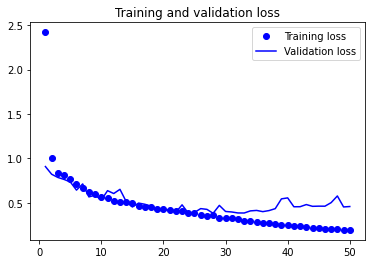
에포크가 25~30 사이즈음에서 과적합이 이뤄지는 것으로 파악됩니다.
이제 마지막으로 저장된 최상의 모델을 가져와 분할 마스크를 예측해 보겠습니다.
#새로운 분할 마스크 예측
from tensorflow.keras.utils import array_to_img
model = keras.models.load_model('oxford.keras')
i = 4
test_image = val_input_imgs[i]
plt.axis('off')
plt.imshow(array_to_img(test_image))#분할 마스크 예측해서 보여주는 함수 선언
def display_mask(pred):
mask = np.argmax(pred, axis = -1)
mask *= 127
plt.axis('off')
plt.imshow(mask)
#예측한 분할 마스크 시각화
mask = model.predict(np.expand_dims(test_image, 0))[0]
display_mask(mask)

많이 부족해 보이지만 어느 정도 잘 예측하는 것을 확인할 수 있었습니다.
이번 포스팅에서는 다양한 컴퓨터 비전의 종류를 알아보았고 그중 이미지 분할에 대해 알아보았습니다.
이미지 분할과 같은 컴퓨터 비전의 딥러닝이 최고의 수준을 가지기 위해서는 아키텍처 패턴(architecture pattern)에 대해 알아야 합니다.
이에 대해서는 다른 포스팅에서 다뤄보도록 하겠습니다.
'Book Review > [케라스 창시자에게 배우는 딥러닝] 리뷰' 카테고리의 다른 글
| The universal workflow of machine learning (4) | 2023.10.24 |
|---|---|
| CNN 훈련하기: cat / dog (3) | 2023.02.21 |
| 합성곱 연산: Convnet / CNN 이해하기 (2) | 2023.02.07 |
| 다양하게 케라스 딥러닝 모델 구축하기 (2) | 2023.01.26 |
| 머신러닝의 목표: 일반화 (2) | 2023.01.11 |



