이번 포스팅에서는 CVPR 2016에 나온 style transfer 논문을 리뷰할 예정이다.
해당 논문은 우리가 원하는 이미지를 원하는 그림 스타일(화풍)에 적용하는 방법을 제시한다.
paper: https://openaccess.thecvf.com/content_cvpr_2016/html/Gatys_Image_Style_Transfer_CVPR_2016_paper.html
CVPR 2016 Open Access Repository
Leon A. Gatys, Alexander S. Ecker, Matthias Bethge; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2414-2423 Rendering the semantic content of an image in different styles is a difficult image processing tas
openaccess.thecvf.com
Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. "Image style transfer using convolutional neural networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
Abstract
앞서 말했듯 본 논문은 이미지의 특성을 사용하여 style transfer를 수행하는 방법을 제안한다.
이때, 이미지의 특성을 추출하기 위해 CNN구조를 사용하여 명시적인 high level information을 활용한다.
결과적으로 content 정보와 style 정보를 분리하여 재결합할 수 있는 artistic style의 neural network 알고리즘을 만들었다.
이 말은 A라는 이미지에서는 content 정보를, B라는 이미지에서는 style 정보를 추출하여 (분리하여)
재결합(recombine)하겠다는 의미이다.
쉽게 정리하면, CNN을 통해 이미지로부터 content / style 정보를 각각 추출하여 content에 style을 적용하는 style transfer를 수행한다!
Introduction
이전에 스타일 변환에 대한 연구는 texture transfer 연구로 시작되었다. 원본 이미지에 texture를 합성하는 것으로 이뤄졌는데,
괄목할만한 결과를 보였지만, 역시 fundamental한 한계점이 명확하다고 한다.
그것은 low level의 image feature를 사용했다는 점이다.
따라서 high level의 feature를 사용하기 위해 CNN을 사용했다.
잘 학습된 CNN으로 high level의 feature를 활용하면, content와 style을 잘 나타낼 수 있음을 Figure 1에서 보여준다.
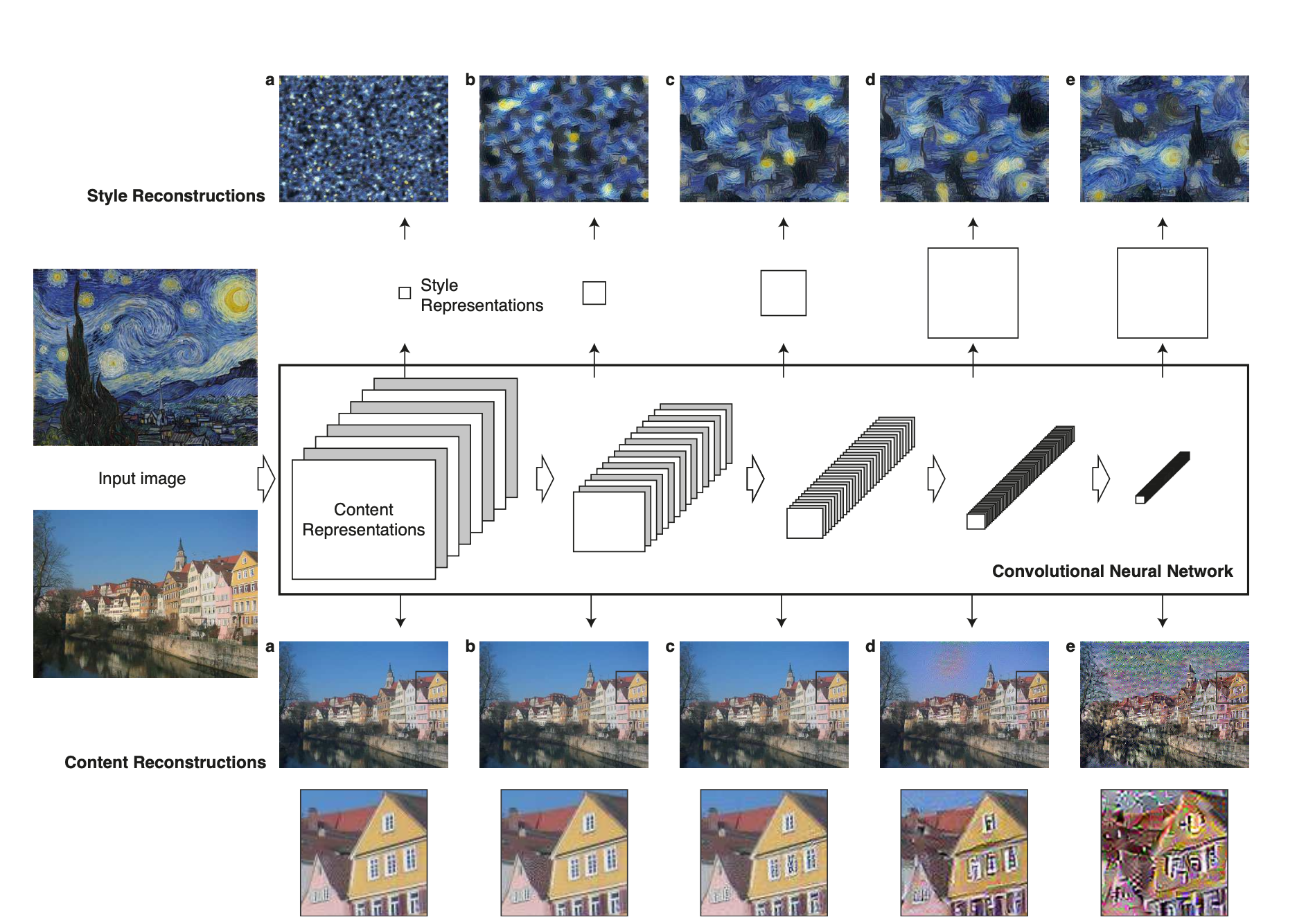
Figure 1에서 보이듯이, content Representations는 input image가 CNN을 통과하면서 나타난
feature map의 각 층에서의 집합으로 표현된다. 본 논문은 이를 활용하여 content와 style에 동시에 적용하도록 한다.
- Content Reconstructions
기존의 VGG network를 구성하는 conv layer를 통과한 feature map을 사용한다. 본 논문에서는 (a)~(e)까지의 content 변환을 수행하는 데 사용된 layer는 각각 conv1_2(a), conv2_2(b), ..., conv_5_2(e)라고 한다.
깊은 층의 feature map을 사용할수록, 즉 (a)->(e)방향으로 갈수록 디테일한 픽셀 정보는 소실되지만,
high level의 특징은 잘 보존된다.
- Style Reconstructions
input image의 화풍을 재현 및 구현하기 위해서 해당 이미지의 texture 정보를 capture 하려고 했다.
texture 정보는 각각의 다른 feature map 끼리의 correlation을 구해 계산된다.
이 때도 역시 conv layer를 통과한 feature map을 사용하는데, content에서 사용된 feature map과 다른 점은
층이 깊어질수록, 중복하여 사용했다는 점이다.
예를 들어, (a)에서는 conv_1, (b)에서는 conv1_1 과 conv2_1, ..., (e)에서는 conv1_1, conv2_1, conv3_1, conv4_1, conv5_1이 사용된다.
Deep Image representations
방금 나타난 content, style reconstruction이 어떻게 수행될 수 있는지 설명하는 파트이다.
설명하기 앞서 해당 논문의 backbone network와 어떠한 기법과 tool로 모델링을 했는지 알려준다.
각 reconstruction을 위해 필요한 feature map은
16 conv + 5 pooling layer로 구성된 19개 layers를 가진 VGG network를 사용한다.
이미지와 위치에 대한 평균 activation이 1이 되도록 normalize를 한다.
feature map을 풀링하거나 정규화하지 않고 linear activation fuction을 조절해 output은 바뀌지 않는다.
FCN을 사용하지 않았고 Caffe framework으로 개발했으며 성능이 더 좋았던 average pooling을 사용했다고 한다.
2.1 Content representation
network의 각 층은 non-linear filter를 쌓았으므로, image x는 CNN의 각 층을 통과하면서 이미지에 대응되는 filter들에 의해
인코딩 된다. 한 layer에
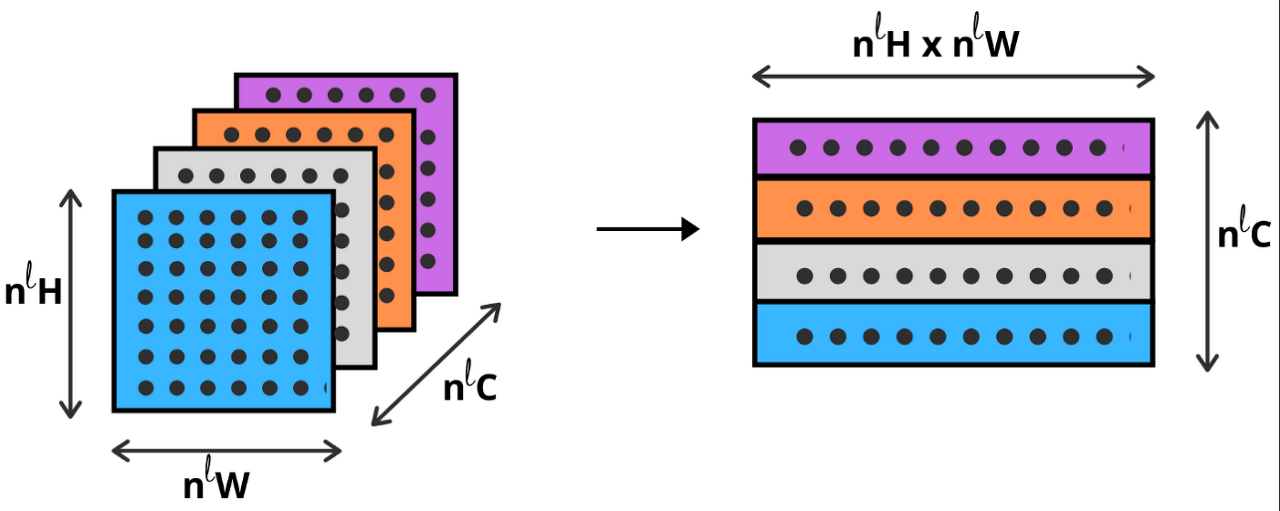
따라서 layer ℓ은 다음과 같은 matrix를 store 할 수 있다.
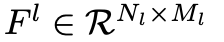
이는 layer ℓ의 activation값을 의미한다.
이미지 정보를 visualize하기 위해 white noise image를 original Image에 대응되는 feature와 맞도록 gradient descent를 실행한다.
다음 식(1)을 보면, 이게 무엇을 의미하는지 더욱 직관적으로 와닿는다.
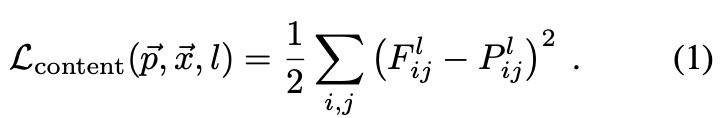
는 원본 이미지, 는 생성된 이미지라고 하면, 과 을 각각 layer ℓ에서 각각 얻어진 feature representations이다.
이 두 feature represntations 사이의 squared-error loss를 정의한 식이 식(1)이다.(content loss)
즉, 정리하자면, original 이미지와 white noise로 생성된 각각의 feature map끼리 squared-error를 최소화하여
각 feature map의 pixel값들을 비슷하게 만들겠다!
target image(여기서는 original image)와 X₁의 white noise image로 Xiters를 구하자는 아이디어.


2.2 Style representation
Image의 style(화풍)은 추출할 image의 texture 정보를 활용한다.
앞서 언급한 것처럼 feature space(map)을 사용하는데,
각기 다른 filter response(= feature map을 사용했다)들에 대해 correlations를 구하여 이를 가능하게 했다.
feature correlations는 layer ℓ에 대한 각각의 feature map을 vectorize 하고 그 값끼리 내적 하여 구했다.
이러한 feature map끼리의 correlations를 Gram matrix라고 명칭했다.
본 논문은 이 Gram matrix를 style representation이라고 한다.
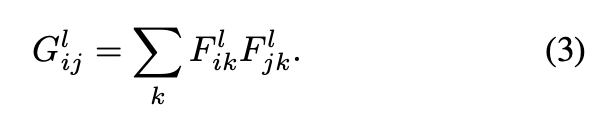
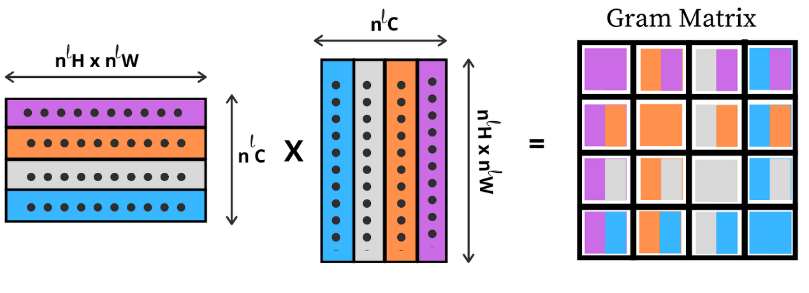
위 content representation과 마찬가지로, original과 white noise image가 특정 layer을 통과한 feature map의 correlation을 구하여 squared-error loss를 구하고 이 값이 최소가 되도록 한다.(= style loss)
따라서 total loss = content loss + style loss가 된다.
논문에서 제안한 전체적인 task의 flow는 다음과 같다.

이 전반적인 알고리즘을 이해한다면 해당 논문에 대한 아이디어와 구현 방식에 대해 이해했다고 볼 수 있을 것이다.
다만 추가된 내용은 total loss에서 각 loss에 대한 가중치 𝛂, 𝛃가 추가되었다는 점이다.
상대적으로 어떠한 loss를 더 많이 반영할지를 조절하게 해주는 hyper parameter이다.
2.3 Style transfer
그림 A의 화풍을 사진 P에 적용된 것을 보여준다.
feature representation의 distance를 최소화하면 style transfer가 잘 수행됨을 나타낸다.
학습 시 L-BFGS optimizer를 사용하였다고 한다.
그 결과는 다음과 같다.

3. Results
본 논문의 key finding은 CNN network로 contetn와 style이 잘 분리되었다는 것이다.
이를 활용하여 새로운 image를 만드는데 독립적인 representation을 사용했다.
이를 증명하기 위해 results에서 Neckar river in Tubingen, Germany의 사진과 artwork를 합성하여 보여준다.
이때 유의할 점은, 스타일 합성을 위한 content representation은 conv4_2의 layer의 출력 feature를 사용했으며,
style representation은 conv1_1, conv2_1, conv3_1, conv4_1, and conv5_1의 layer의 출력을 복합적으로 사용했다.
각 층에 대해 동일한 가중치로 feature를 사용했다고 한다. (wl = 1/5 in those layers, wl = 0 in all other layers)
3.1 Trade-off between content and style matching

합성이 완벽하게 수행될 수는 없다.
따라서 total loss를 정의할 때, 어떠한 loss에 상대적인 가중을 둘 지 정하는 것이 중요하다.
content에 가중을 두면 style이 잘 합성되지 않으며, 반대의 경우 content가 잘 나타나지 않는 모습을 보인다.
Figure 4를 보면 content/style의 비율을 나타내는 데,
왼쪽 상단의 경우 style이 content의 10,000배 가중되는 파라미터(𝛃 = 10000 * 𝛂 )를 가질 때의 결과를 보여준다.
이는 content와 style 간의 trade-off 관계를 잘 나타내준다.
3.2 Effect of different layers of the Convolutional Neural Network
또 다른 중요한 요소는 layer의 어떤 층을 사용하여 feature를 활용할 것인지와 관련있다.(layer 설정과 관련된 내용)
style representation은 Neural Network의 여러 layer에서 multi-scale로 표현되는데
각 layer들은 local scale을 결정하고 그에 따라서 다른 결과가 나타난다.
higher layer까지 이용하게 된다면 더 큰 규모의 local image structure를 보존할 수 있고, 스타일 정보를 적절하게 바꿀 수 있다.
즉, higher layer의 출력까지 중복하여 사용한다면 더 자연스럽고 부드럽게 시각적인 변환을 보일 수 있는 style representation을 만들 수 있는 것이다. 따라서 본 논문은 conv1_1~conv5_1의 레이어들의 style features를 사용했다고 한다.
마찬가지로 content representation에 대해서도 같은 실험을 수행한 결과,
lower layer에 대해서는 fine structure를 보존하는 반면 higher layer를 사용하면 detail 한 pixel정보가 유실되는 것을 볼 수 있다.
Figure 5를 보면 이를 직관적으로 확인할 수 있다.

3.3 Initialisation of gradient descent
grdient descent를 진행할 때, 초기의 이미지를 어떻게 설정하느냐에 따라 결과가 바뀐다는 것을 실험으로 보여줬다.

A는 content 이미지로부터 초기값을 설정한 경우이고 B는 style 이미지로 초기화하여 style transfer를 수행했을 때의 결과이다.
C는 각가의 다른 random noise로 출발한 결과이다. 이 모든 결괏값이 다 다름을 알 수 있다.
3.4 Photorealistic style transfer
그림이 아닌 사진끼리의 style transfer도 잘 수행하는 모습을 보인다는 것을 실험으로 보여준다.
밤에 찍은 뉴욕사진과 낮에 찍은 런던 사진을 1 : 100 수준으로 합성했더니 잘 합성된 것을 보여준다.

References
[1] https://www.youtube.com/watch?v=va3e2c4uKJk&list=PLRx0vPvlEmdADpce8aoBhNnDaaHQN1Typ&index=13
'인공지능 > Paper Review' 카테고리의 다른 글
| [Paper Review] YOLACT: Real-time Instance Segmentation (0) | 2024.03.27 |
|---|
