
이번 포스팅에서 생성 모델링 문제를 '순차적'으로 다루는 자기회귀 모델에 대해 알아보자.
자기회귀 모델은 생성 문제를 순차적인 과정으로 다뤄 단순화한다.
앞 장에서 살펴본 VAE, GAN과는 달리 잠재 확률 변수를 사용하지 않고 시퀀스에 있는 이전 값을 바탕으로 예측을 만든다.
따라서 데이터 생성 분포를 근사하는 것 보다는 명시적으로 이를 모델링 한다는 점에서 차이가 있다.
1. LSTM
LSTM은 순환 신경망의 한 종류이다.
순환 신경망에는 순차적인 데이터(텍스트 데이터, 시계열 데이터 등)을 처리하는 순환 층(셀)이 있고,
특정 타임 스텝에서 셀의 출력이 다음 타임 스텝의 입력으로 사용된다.
재귀적으로 되먹이는 구조를 가지는 네트워크이기 때문에 recurrent neural netwrok, RNN으로 쓰인다.
처음 RNN은 장기 의존성(long-short term memory )의 문제를 가지고 있었다.
현재 타임 스텝에서 멀리 떨어진 타임 스텝에서의 셀의 출력이 현재 타임 스텝에 전혀 영향을 미치지 못하는 것을 의미한다.
그 원인은 그레이디언트 소실 문제이며, 따라서 긴 시퀀스에서는 사용하기 어렵다는 단점이 있었다.
이 문제를 해결하고자 나온 모델이 LSTM이다.
LSTM의 셀은 RNN의 그레이디언트 소실 문제를 해결하여 긴 타임 스텝 동안 시퀀스를 훈련시킬 수 있었다.
LSTM의 어떤 구조가 이를 가능하게 했는 지 알아보자.
1.1 LSTM 셀
LSTM의 셀은 이전 은닉 상태 h𝘵₋₁ 와 현재의 단어 임베딩 𝑿𝘵 가 주어졌을 때 새로운 은닉 상태 h𝘵를 출력한다.
아래의 그림 15-6을 보면서 이해해보자.

하나의 LSTM 셀은 셀 상태(C𝘵)를 관리한다. 셀 상태는 현재 시퀀스의 상태에 관한 내용을 담고 있다고 보면 된다.
셀 상태 C𝘵 와 은닉 상태 h𝘵를 업데이트 하면서 LSTM의 셀이 매 시퀀스마다 작동한다.
그림 5-6을 보면 은닉 상태와 셀 상태의 업데이트가 어떻게 이뤄지는 지와 그 흐름에 대해 알 수 있다.
셀 상태와 은닉 상태는 다음과 같은 단계를 거쳐 업데이트 된다.
1. 이전 타임 스텝의 은닉 상태 h𝘵₋₁ 는 현재 단어 임베딩 𝑿𝘵 와 연결 되어(연결된 벡터 V) 삭제 게이트로 전달(이전 셀 상태 C𝘵₋₁ 를 얼마나 유지할 지 결정)
2. 벡터 V는 입력 게이트로 전달 (이전 셀 상태 C𝘵₋₁ 에 얼마나 새로운 정보를 추가할 지 결정)
3. 벡터 V는 완전 연결층으로 전달 되어 벡터 ć𝘵를 생성(셀이 저장하려는 새로운 정보를 담기)
4. 4번 식을 통해 C𝘵를 만드는 과정(이전 셀 상태의 일부분을 삭제하고 새로운 정보를 더해 업데이트)
5. 벡터 V는 가중치 행렬 Wo, 편향 bo가 시그모이드로 넘어간다. 출력 게이트로도 넘어감
6. 업데이트된 셀 상태 C𝘵가 6번 식에 의해 새로운 은닉 상태 h𝘵를 생성
2. PixelCNN
텍스트 데이터가 아닌 이미지, 영상 데이터에서도 자기회귀 모델을 사용할 수 있다.
같은 아이디어로 이전 픽셀을 기반으로 다음 픽셀의 likelihood를 예측해 픽셀 단위로 이미지를 생성하는 모델이다.
PixelCNN이 그 모델 중 하나이다.
자기회귀 모델은 시퀀스 데이터가 필요하다. 하지만 이미지 데이터에는 순서가 지정되어 있지 않다.
일반적인 CNN은 모든 픽셀을 동등하게 처리하여 어떤 픽셀도 이미지의 시작이나 끝으로 판단하지 않는다.
우리가 픽셀에 순서를 정해줘야 한다.
일반적으로 픽셀의 순서는 왼쪽 위에서 오른쪽 아래로 행을 따라 이동하고 그 다음 열을 따라가는 개념이다.
순서가 지정된 픽셀을 필터가 해당 픽셀 앞부분만 보고 판단해야한다.
이를 통해 다음 픽셀의 값을 예측하면서 한번에 한 픽셀씩 이미지를 생성해내는 것이다.
PixelCNN에서 중요한 것은 이미지를 자기회귀 방식으로 생성한 다는 아이디어와 이를 효과적으로 구현하기 위해
masked convolution layer, residual block의 개념을 도입했다는 것이다. (최초로 도입한 것은 아님)
이를 하나씩 살펴보면서 개념을 이해해보자!
2.1 Masked convolution layer(마스크드 합성곱 층)
앞서 말했듯 우리가 생성하고자 하는 현재 픽셀의 앞부분만 보고 해당 픽셀을 예측해야한다.
이렇게 하기 위해서 필요한게 masked convolution layer이다.
필터를 마스킹하여(conv연산을 할 때) 이를 구현한다.
이렇게 하면 1과 0으로 구성된 mask에 필터 가중치 행렬을 곱하여 현재 픽셀 뒤에 있는 모든 픽셀의 값이 0이 된다.
각 픽셀의 층 출력이 해당 픽셀 앞에 있는 픽셀 값에서 추론되어야하기 때문에 중앙 픽셀이 마스킹 된 mask A와,
중앙 픽셀이 마스킹되어 있지 않은 mask B가 있다.

두 종류의 마스크가 있는 이유는 초기 masked conv layer에서는 중앙 픽셀이 신경망이 예측해야 할 픽셀 값이기 때문이고,
후속 masked conv layer에서 예측된 중앙 픽셀 값을 바탕으로 그 다음 픽셀이 예측되어야 하기 때문이다.
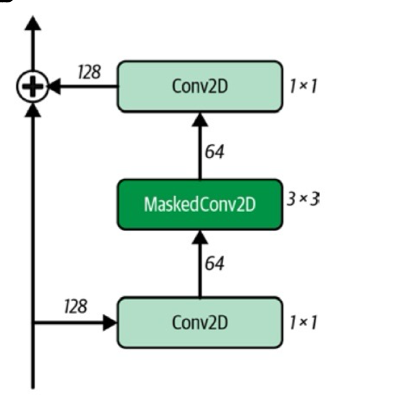
2.2 Residual block (잔차 블록)
잔차 블록은 신경망의 나머지 부분에 출력이 전달되기 전의 입력과 더해지는 층의 블록을 의미한다.
이를 skip connection이라고 하는데, 간단히 표현하면 y = x + f(x)와 같은 꼴이다.
(x가 입력, f(x)가 층의 출력)
잔차 블록 층은 gradient vanishing 문제를 해결하여 원활한 모델의 학습을 도와 일반화의 성능을 높인다.
PixelCNN에서 residual block은 다음과 같다.
conv + masked conv + conv를 통과한 layer의 출력을 layer의 입력과 더한다.
'Book Review > [만들면서 배우는 생성형 AI] 리뷰' 카테고리의 다른 글
| 8장. 확산 모델(diffusion model) (1) | 2024.06.04 |
|---|---|
| 6장. 노멀라이징 플로 모델(normalizing flow model) (1) | 2024.05.16 |
| 4장. 생성적 적대 신경망(GAN) (0) | 2024.04.17 |
| 3장 - 변이형 오토인코더 (VAE) (0) | 2024.03.26 |
| 2장 - 딥러닝 (2) | 2024.03.18 |



