
이번 포스트에서는 파이썬을 활용하여 데이터 전처리 하는 방식에 대해 혼공머신 예제를 통해 알아보도록 하겠습니다.
1. 지도학습(supervised learning)이란?
들어가기에 앞서, 지도학습(supervised learning)과 비지도학습(unsupervised learning)에 대해 알아보겠습니다.
이전 포스트에서는 knn 알고리즘을 활용하여 도미와 빙어를 구분하는 간단한 머신러닝 모델을 만들어 보았습니다.
도미와 빙어를 구분하기 위해서는 어떠한 데이터가 필요했는지 기억이 나시나요?
도미, 빙어의 길이와 무게 데이터와 각각의 길이, 무게 데이터가 도미인지 빙어인지 정답을 알려주는 정답 데이터가 있었습니다.
이처럼 입력(input, 여기서는 도미와 빙어의 길이,무게), 타깃(target, 도미, 빙어 여부)을 가지고 학습하는 것을 지도학습 이라고 합니다.
즉, 지도학습에는 입력과 타깃(특성 데이터와 정답)이 있어야 합니다. 이 둘을 합쳐서 훈련 데이터(training data)라고 부릅니다.
지도 학습은 정답이 있기 때문에 알고리즘이 정답을 맞히는 것을 학습합니다.
반면, 비지도 학습은 입력 데이터만 가지고 학습을 진행합니다. 타깃 데이터 없이 오직 입력 데이터만 이용하여 컴퓨터를 학습시킵니다.
강화 학습은 보상을 통해 상을 최대화 하고 벌은 최소화 하여 agent가 행위를 강화하는 학습을 의미합니다.
(비지도 학습과 강화 학습의 보다 자세한 예시는 다른 포스트에서 언급하도록 하겠습니다.)

그림 1에서 보이듯이 지도 학습은 예측, 분류 문제에 자주 활용되고, 비지도 학습은 연관 규칙, 군집을 통한 문제 해결에 자주 활용됩니다.
2. 훈련 세트와 테스트 세트의 중요성
데이터를 전처리하기 전 또 하나 알고 넘어가야 할 것이 있습니다.
바로 훈련 세트와 테스트 세트의 중요성입니다.
컴퓨터가 학습을 할 때 훈련 세트로 훈련을 하고 같은 데이터로 테스트를 한다면 당연히 다 맞출 것입니다.
쉽게 예를 들어보겠습니다.
xx고등학교를 다니는 김머신은 수학 시간에 선생님이 시험 문제는 수학익힘책 어떤 문제에서 나오는 지 다 알려줬다고
수학 익힘책 해당 문제만 풀었습니다. 정답을 외우기만 해도 실수만 하지 않는다면 김머신은 수학 시험 문제를 다 맞추겠죠?
당연한 결과입니다. 더더욱 컴퓨터는 실수를 할 리가 없죠.
훈련 데이터로 똑같이 학습하고 똑같이 평가하는 것은 머신러닝의 알고리즘의 성능을 제대로 알려주지 못합니다.
따라서 머신러닝 알고리즘의 성능을 제대로 평가하려면 훈련 데이터와 테스트 데이터가 각각 달라야합니다.
훈련 데이터와 테스트 데이터를 다르게 하는 가장 간단한 방법은 (1)테스트를 위한 또 다른 데이터를 준비하거나 ,
(2)이미 가지고 있는 데이터 중에서 일부를 떼어내 테스트에 사용하는 것 입니다.
훈련에 사용되는 데이터를 훈련 세트, 평가에 사용되는 데이터를 테스트 세트라고 합니다.
3. 데이터 전처리
-샘플링
이전 포스트에서 활용한 데이터를 가지고 샘플을 처리해 보겠습니다.
여기서 샘플이란 여러특성을 하나의 데이터로 집합시키는 것을 의미합니다.
(여기서는 각 생선의 길이와 무게를 하나의 리스트로 담은 2차원 리스트를 만드는 것이 샘플을 처리하는 것이 될 것입니다.)
이전 포스트의 데이터와 비슷한 데이터를 우선 준비해줍니다.
해당 코드는 다음과 같습니다.
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
이제 두 파이썬 리스트를 순회하면서 각 생선의 길이와 무게를 하나의 리스트로 담아 2차원 리스트를 만들어보겠습니다.
해당 코드는 다음과 같습니다.
fish_data = [[l,w] for l,w in zip(fish_length, fish_weight)]
fish_target = [1] * 35 + [0]*14

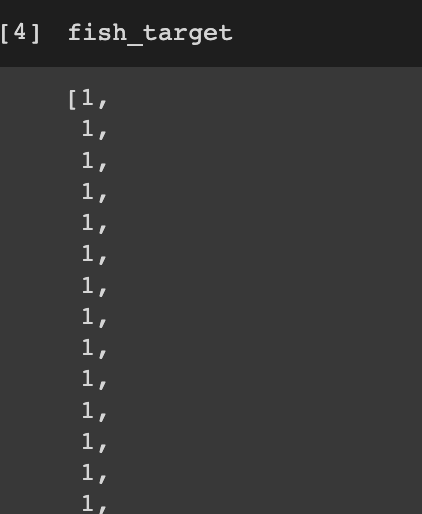
fish_data에는 2개의 특성으로 훈련 세트 35개, 테스트 세트 14개로 하여 총 49개의 샘플을 만들었습니다.
fish_target에는 훈련 세트와 테스트 세트에 대한 총 49개의 정답 데이터 샘플을 만들었습니다.
- 인덱스 / 슬라이싱
일반적으로 리스트처럼 배열 형태에서 요소를 선택할 때 배열의 위치를 지정합니다.
이 때 필요한게 인덱스(index) 입니다.
책을 보면 첫 부분에 목차(index)가 있는 것을 보았을 것입니다.
그 개념으로 이하하시면 됩니다.
마찬가지로 인덱스에도 순서가 있습니다. 배열의 인덱스는 0부터 시작한다는 특징이 있습니다.
앞서 만든 샘플 데이터 기반의 코드로 예시를 들어보겠습니다.
print(fish_data[4])
fish_data[4]는 fish_data 배열의 5번째 인덱스에 접근해라! 라는 의미입니다.
(fish_data[0] 는 [25.4, 242.0]로 첫번째 인덱스 입니다.)
파이썬 리스트는 인덱스 외에도 슬라이싱(slicing)이라는 특별한 연산자를 제공해줍니다.
슬라이스를 통해 인덱스의 범위를 정해주고 여러가지 원소를 뽑아낼 수 있습니다.
슬라이스 예시도 코드로 확인해보겠습니다.
print(fish_data[0:5])이 코드는 "fish_data에서 0~4까지의 인덱스를 뽑아줘!" 라고 하는 것을 의미합니다.
여기서 추가적으로 알아두면 좋은 것은 파이썬에서 슬라이싱 마지막 인덱스의 원소는 포함되지 않는다는 것입니다.
따라서, [0:5]는 첫번째 인덱스부터 네번째 인덱스까지만을 선택합니다.
또한 처음 시작하는 슬라이싱 인덱스가 0인 경우 생략할 수 있습니다. (fish_data[0:5]와 fish_data[ :5]는 같은 의미)
인덱스와 슬라이스를 알면 배열 형태의 데이터에서 원하는 원소들을 불러올 수 있어 편리합니다.
-넘파이(numpy)
넘파이는 파이썬에서 제공하는 대표적인 배열 라이브러리입니다.
머신러닝, 딥러닝에서 배열은 고차원의 배열입니다. 이를 직접 연산하고 표현하려면 굉장히 번거롭습니다.
따라서 넘파이는 고차원의 배열을 손쉽게 만들고 조작하는데 특화된 도구를 많이 제공합니다.
넘파이를 사용하기 위해서는 먼저 넘파이 라이브러리를 임포트해야 합니다.
코드는 다음과 같습니다.
import numpy as np이 코드의 의미는 "넘파이 라이브러리를 임포트할건데 나는 이걸 np라고 부를거야." 라고 하는 것과 같습니다.
넘파이 배열을 임포트했으면 넘파이 계산을 하기 위해 데이터를 넘파이 배열로 바꿔야 합니다.
넘파이 배열로 바꾸는 것은 array()함수를 사용하면 됩니다.
예시 코드는 다음과 같습니다.
input_arr = np.array(fish_data)
target_arr = np.array(fish_target)앞서 만든 2차원 리스트형태의 샘플이 np.array()함수에 전달되어 2차원 넘파이 배열로 바꾸었습니다.
넘파이 배열이 어떻게 생겼는지 코드를 통해 출력해보겠습니다.
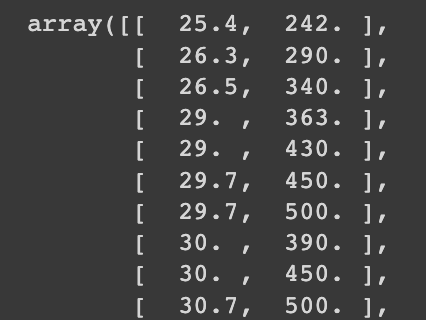
이전에 봤던 것과 형태는 동일합니다. 형태적으로는 같을지 모르지만 넘파이 연산을 하기 위해서 넘파이 배열로 바꾸는 것을 잊지마세요!
넘파이는 인덱싱, 슬라이싱 이외에 배열 인덱싱이라는 기능을 제공해줍니다.
1개의 인덱스가 아닌 여러개의 인덱스로 한 반에 여러개의 원소를 출력할 수 있게 해줍니다.
슬라이싱과 같은 개념이지만 경우에 따라 편리하게 사용할 수 있습니다.
코드로 예시를 들어보겠습니다.
print(input_arr[[1,3]])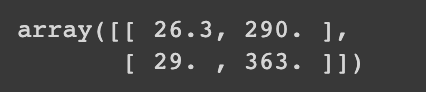
위 데이터에서 확인할 수 있습니다.
input_arr의 넘파이 배열에서 2번째, 4번째 인덱스에 해당하는 샘플을 출력한 것을 알 수 있습니다.
이번 포스트에서는 1.모델의 성능을 평가하기 위해서 훈련 세트와 테스트 세트를 나누어야 한다는 것과
2.데이터 전처리에서 자주 사용되는 인덱스, 슬라이싱 기법과 넘파이 라이브러리를 사용하는 법에 대해 간단하게 알아보았습니다.
'Book Review > [혼공머신] 리뷰' 카테고리의 다른 글
| 로지스틱 회귀 (0) | 2023.01.04 |
|---|---|
| 다중회귀 & 릿지, 라쏘회귀 (2) | 2022.12.08 |
| 기본적인 회귀 알고리즘: 선형회귀, 다항회귀 (0) | 2022.12.07 |
| 데이터 전처리 기초 with python (2) (0) | 2022.11.24 |
| k-최근접 이웃을 통한 분류 모델 훈련 (2) | 2022.11.16 |



